
Искусственный интеллект в распознавании рака лёгкого
По прогнозам корпорации EMC, объём сгенерированных человечеством данных к 2020 г. будет в 57 раз больше байт, чем песчинок на всех пляжах планеты – 40 зеттабайт. Однако, самым сложным представляется не хранение, но обработка big data.
А.А. Мелдо1,2, Л.В. Уткин2, В.М. Моисеенко1
1 Санкт-Петербургский клинический научно-практический центр
специализированных видов медицинской помощи (онкологический)
2 Санкт-Петербургский Политехнический университет
Петра Великого
В настоящее время количество цифровой информации стремительно растёт, опережая даже увеличение производственных мощностей компьютеров. Впервые это было названо Big data (большие данные) журналом Nature в 2008 г. По прогнозам корпорации EMC, объём сгенерированных человечеством данных к 2020 г. будет в 57 раз больше байт, чем песчинок на всех пляжах планеты – 40 зеттабайт. Однако, самым сложным представляется не хранение, но обработка big data. Искусственный интеллект (ИИ) в целом – это технология создания умных программ и машин, которые могут решать необходимые задачи и генерировать новую информацию на основе имеющейся.
Фактически искусственный интеллект призван моделировать человеческую деятельность, которая считается интеллектуальной. Одной из наиболее перспективных точек приложения для применения технологий ИИ, по мнению ряда исследователей, – это медицина. В статье приводится обзор основ и алгоритмов искусственного интеллекта на базовом уровне, показаны перспективы использования автоматизированных систем принятия решений в диагностике рака лёгкого.
Предпосылки и контекстное понимание искусственного интеллекта или «как это работает»
Количество рентгеновских исследований, включая компьютерную томографию, ежегодно увеличивается на 1–2% [1]. Разработка автоматизированных средств принятия решений в рентгенологии началась в 50-х годах прошлого века [2], и сегодня можно с уверенностью сказать, что основным элементом автоматизации в этой области становится искусственный интеллект (ИИ) и его основная часть – машинное обучение (МО).
В настоящее время под искусственным интеллектом понимается одно из направлений информационных технологий, которое связано с изучением и разработкой систем, моделирующих возможности человеческого интеллекта, таких как способность к обучению, логическому рассуждению, выводу и принятию решений. Это стало возможным благодаря глубокому изучению биологических свойств нервной системы человека, междисциплинарному анализу механизмов передачи информации на стыке специальностей с медико-биологической, математической, компьютерно-технологической направленностью.
Под способностью искусственного интеллекта к обучению, прежде всего, понимается специально организованный, управляемый процесс совершенствования характеристик работы информационной системы на основе имеющихся данных.
В зависимости от пути достижения результата, системы ИИ можно разделить на три основные группы: с дедуктивным, индуктивным и смешанным выводом.
Дедуктивный вывод (от общего к частному) связан с началом истории ИИ, а именно этапом, когда основным его инструментом являлись т.н. экспертные системы, функционирование которых похоже на то, как опытный врач учит ординатора – он использует свой опыт и передаёт его в виде определенных правил, обычно вида «если-то». Достаточно обратиться к учебнику Л.Д. Линденбратена с алгоритмами анализа рентгенограммы лёгких с синдромом круглой тени [3] (рис. 1).
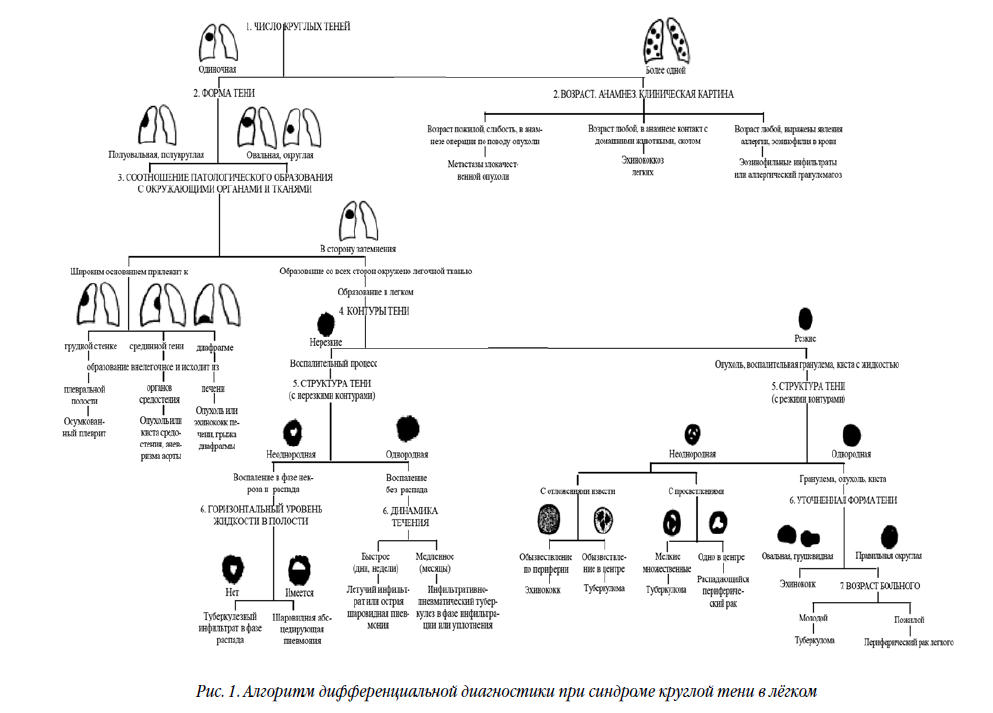
Недостатком такого подхода является факт невозможности предусмотреть правила «на все случаи жизни», особенно если эти случаи были ранее неизвестны. Кроме того, общие правила, даже полученные от высококвалифицированного эксперта, не всегда дают верный вариант решения.
Индуктивный вывод (от частного к общему) решает противоположную задачу. На основе имеющихся данных, например, множества снимков компьютерной томографии (КТ) пациентов с раком лёгкого, происходит т.н. обучение системы. Вначале система пытается обобщить и выделить общие закономерности из представленных данных. Далее она выстраивает такие правила или алгоритмы, которые в дальнейшем могли бы делать выводы из новых данных. Данный подход лежит в основе большинства современных алгоритмов ИИ.
Машинное обучение – это часть ИИ, которая изучает методы построения алгоритмов, обучения системы на имеющихся данных (например, историях болезней, рентгеновских и КТ снимках, фотографиях и т.д.), которые впоследствии смогут быть инструментом для распознавания новых данных (новых пациентов) или прогнозирования, реализуя индуктивный вывод.
По аналогии с обучением человека методы МО решают несколько типов задач. Первый тип – это обучение с учителем (supervised learning), когда каждый пример данных, например, узловое образование на КТ снимке, определённым образом размечено, что для машины определяет принадлежность этого примера к тому или иному классу (раку лёгкого). Обучить систему без этих меток классов невозможно. Применительно к диагностическому процессу задачей является построение алгоритма классификации на основе помеченных объектов. Таким образом, человек является «учителем» для системы, размечая объект (узловое образование) на снимке. Результат использования этого алгоритма – определение системой к какому классу относится новый объект (например: злокачественное или доброкачественное образование).
Второй тип задач – это обучение без учителя (unsupervised learning), когда обучающие данные не имеют меток принадлежности тому или иному классу, человек не участвует в разметке объектов, система сама выделяет различия на представленных данных.
Третий тип – это активное обучение (active learning), когда размеченных данных мало или их нет (без учителя) и эксперт «вмешивается» в процесс обучения, чтобы, например, выбрать наиболее «ярких» представителей некоторого класса, а затем автоматически разметить все ближайшие, по некоторой метрике расстояния, к ним данные.
Четвертый тип – это обучение с подкреплением (reinforcement learning), когда система обучается сама, получая «вознаграждения» или «штрафы» при выполнении определенных действий [4]. Все описанные в литературе алгоритмы диагностики заболеваний используют первый тип задач – обучение с учителем, таким образом, роль человека в развитии ИИ в настоящее время неоспорима.
Еще один важный тип задачи МО – это т.н. задача отбора признаков (feature selection), когда по обучающим данным определяется, какие факторы или признаки в наибольшей степени влияют или не влияют на отнесение данных к тому или иному классу. Например, ширина просвета аорты не влияет на дифференциальную диагностику рака легкого, что позволяет не рассматривать этот признак, тогда как нечёткость контура образования в лёгком и наличие радиарных тяжей являются значимыми признаками.
Одновременно, можно сказать, что МО действительно является мощным инструментом только в том случае, когда результат достижим с теми данными, которые имеются у нас в распоряжении.
В целом, важно отметить, что сегодня МО следует рассматривать как помощника при решении задач, особенно медицинских, в аспекте того, что «человек мог бы решить проблему, но компьютер сделает это быстрее». Вместе с тем, имеется ряд публикаций об эффективности ИИ в диагностике меланомы, превышающей способности человека [5, 6].Так в работе H.A. Haenssle и соавт. описано, что алгоритм обучения на основе сверточной нейронной сети поставил правильный диагноз в 95% случаев, тогда как результат анализа 58 профессиональных дерматологов составлял 86,6% [6].
Несмотря на большое количество различных методов МО и успешное применение их в медицине, наиболее значимые результаты для применения в диагностике были получены с использованием нейронных сетей и, в частности, сверточных нейронных сетей, которые в настоящее время принято называть инструментом глубокого обучения (deep learning).
Каждый нейрон в сети является отдаленным аналогом биологического нейрона с точки зрения его функционирования или интерпретации (рис. 2).

Вспомним принцип работы нейрона как структурно-функциональной единицы нервной системы млекопитающих. При раздражении чувствительной части нейрона происходит изменение проницаемости мембраны для заряженных ионов калия и натрия, происходит смена полярности на данном участке нейрона. Ионы генерируют электрический заряд (потенциал действия), который приводит к открытию натриевых и кальциевых каналов на терминальном конце аксона пресинаптического нейрона. Ионы натрия и кальция, проникающие в клетку, запускают механизм выхода нейротрансмиттеров в синаптическую щель (экзоцитоз). Нейротрансмиттеры связываются с рецепторами на постсинаптическом нейроне, что способствует открытию натриевых каналов (трансмиттерзависимых), процесс повторяется. Передача импульса невозможна, если не возникнет потенциал действия.
Нейрон в МО – это функция-классификатор, который сравнивает весовую сумму (вклад каждого признака) входных данных с некоторым числом (порогом активации). При превышении порога активации (суммарный вклад признаков значителен) он на выходе выдает один результат классификации, если порог активации не превышен – другой результат.
При комбинировании множества нейронов, которые образуют нейронную сеть (НС), можно реализовать практически любую математическую функцию входных данных. При этом реализовать такую функцию означает обучить НС на наборе данных путем вычисления оптимальных весов соединений нейронов.
Основной проблемой обучения НС является то, что для этого необходимо иметь обычно очень большое количество данных (тысячи снимков). Это отличает ИИ от человека, который, пройдя курс рентгенологии, сможет распознавать злокачественные и доброкачественные опухоли на снимках КТ, обучившись по нескольким десяткам примеров. Другим недостатком НС является ее «закрытость».
Мы не можем знать, как выглядит обученная функция, как осуществляется обработка информации и как делается вывод о заболевании [7].
Первую проблему НС удалось частично снять созданием т.н. сверточных НС (СНС). Этот алгоритм в настоящее время признан наиболее эффективным применительно к медицинским изображениям, имеющим большую размерность.
Таким образом, проведем аналогии: потенциал действия в биологическом нейроне = порог активации в математической модели, заряженные ионы = входные данные, биологический вставочный нейрон = слой НС, нейротрансмиттеры = веса признаков и т.д.
Еще одним алгоритмом МО, помимо нейронных сетей, который позволяет проследить процесс обработки информации является т.н. случайный лес или ансамбль деревьев решений. Деревья решений внешне напоминают упорядоченную систему правил, принятую в экспертных системах, так как имеют разветвляющуюся структуру, в которой входные данные расщепляются по одиночному признаку каскадным способом. Например: из всех имеющихся образований на компьютерных томограммах одни – шаровидные, другие – нет, из всех шаровидных, одни имеют ровный контур, другие – полициклический и т.д. (рис. 3).

Как видно из рисунка 3, если разделить множество на две части, то одна из них будет содержать одни значения признаков, а другая – противоположные.
Расщепление прекращается, когда подмножество данных с определенным набором значений признаков становится мало.
Множество случайно построенных деревьев образует случайный лес, являющийся одним из лучших методов МО. Название «случайный» получено из того факта, что каждое дерево строится на подмножестве случайно выбранных данных из всего обучающего множества и на подмножестве случайно выбранных признаков. При этом каждое дерево как бы «голосует» за принадлежность объекта к определённому классу.
Таким образом, на основе того, какая часть деревьев «проголосовала» за тот или иной класс – можно заключить с какой вероятностью объект принадлежит к тому или иному классу (рак легкого или иное заболевание).
Случайный лес относится к т.н. неглубоким алгоритмам МО, а каскад случайных лесов, названный глубоким лесом, относится уже к глубоким алгоритмам обучения [8]. Метод был усовершенствован путем «взвешивания» всех деревьев решений в глубоком лесе. При этом веса деревьев вычисляются в процессе обучения оптимальным образом [9].
Рак лёгкого и машинное обучение
Бурное развитие систем диагностики рака лёгкого на основе данных КТ обусловлено созданием СНС, как основы глубокого обучения, совершенствованием «неглубоких» методов МО, а также их комбинированием. Количество алгоритмов МО, разработанных в последние два десятилетия, посвященных диагностике рака легкого, огромно. Сегодня это целое направление исследований, ориентированное на повышение точности обнаружения и распознавания образований в легких. В настоящее время разработаны две полностью автоматизированные системы диагностики рака лёгкого: Deep Lung [12] и Nodule Х [16]. Авторы этих исследований использовали для обучения и тестирования систем доступные базы данных LIDC и LUNA, которые насчитывают более 1,5 тысяч КТ лёгких.
По данным литературы, процедура обнаружения новообразований в легких на основе изображений КТ обычно состоит из следующих этапов или подсистем: сбор данных, предварительная обработка изображения, сегментация, обнаружение образований, сокращение числа ложноположительных случаев, классификация новообразований [10–12].
Этап сбора данных определяется способом получения медицинских изображений. В основном используются либо результаты проведенных КТ, которые получены в больницах или научных центрах, либо открытые базы данных. Одними из известных и популярных баз данных являются LIDC (Lung Image Database Consortium) и LUNA16 (Lung Nodule Analysis 2016 Challenge) [13, 14].
Основная цель этапа предварительной обработки заключается в обнаружении всех «подозрительных» образований путем фильтрации тканей легких. На этом этапе отделяется область исследования (лёгочная ткань) от других органов и тканей грудной клетки (органы средостения, мягкие ткани грудной стенки, костные структуры), чтобы уменьшить вычислительную сложность следующих этапов.
Сегментация подразумевает процесс «отделения» новообразований от нормальной ткани и органов на изображениях КТ. В соответствии с этой процедурой данные или значения пикселей в каждом изображении преобразуются в значения т.н. рентгеновской плотности по шкале Хаунсфилда.
Целью этапа обнаружения новообразований в лёгком является определение их наличия и локализации.
Основная проблема, которая должна быть решена, заключается в том, чтобы отличить патологические и анатомические структуры. Основными источниками ошибок являются образования, прилежащие к крупным сосудам, рёберной плевре, средостению, диафрагме [15]. Таким образом, к сожалению, на этом этапе остается много ложноположительных случаев, которые характеризуются неправильно идентифицированными образованиями.
Сокращение числа ложноположительных случаев является наиболее сложным в реализации этапом.
Его целью является повышение специфичности диагностического алгоритма МО.
Заключение: искусственный интеллект как предмет неофобии или незаменимый помощник врачу ХХI века
Таким образом, авторы хотели показать, что стремительное увеличение количества информации в мире, и в медицине в частности, является предпосылкой для поиска новых, наиболее эффективных путей обработки big data. Приведенные в статье схемы построения алгоритмов ИИ показывают, что диагностика может являться значимой точкой приложения для их развития.
Особенность ИИ – способность самосовершенствоваться в процессе получения новых, даже фрагментарных и неполных обучающих данных, в отличие от медицинского персонала, который должен постоянно обновлять свои знания в рамках повышения квалификации из различных источников.
Вместе с тем, процесс принятия решения у профессионала основывается не только на анализе паттернов заболевания на полученных изображениях, а на комплексе сведений, включающих анамнестические, клинические, лабораторные данные, и даже, в некоторой степени, интуиции. Таким образом, постоянное взаимодействие рентгенолога и ИИ с точки зрения взаимного обучения позволит значительно повысить качество принимаемых решений как системы, так и врача.
Это означает, что рентгенология в привычном понимании вовсе не изжила себя, как представляется определённой части врачебного сообщества. Наоборот, использование ИИ в автономном режиме представляется недостижимым как с психологической, так и с юридической точек зрения. Однако, выступая в роли помощника, ИИ позволит диагносту принимать более обоснованные решения, избавит его от множества рутинных дел. Рентгенологи ХХI века – это главные лица в системе отношений «врач-ИИ», успешно реализующие свой потенциал на новом уровне.
Источник: Журнал "Практическая онкология" №3, 2018
Источник: https://vrachirf.ru